Data Bias Definition
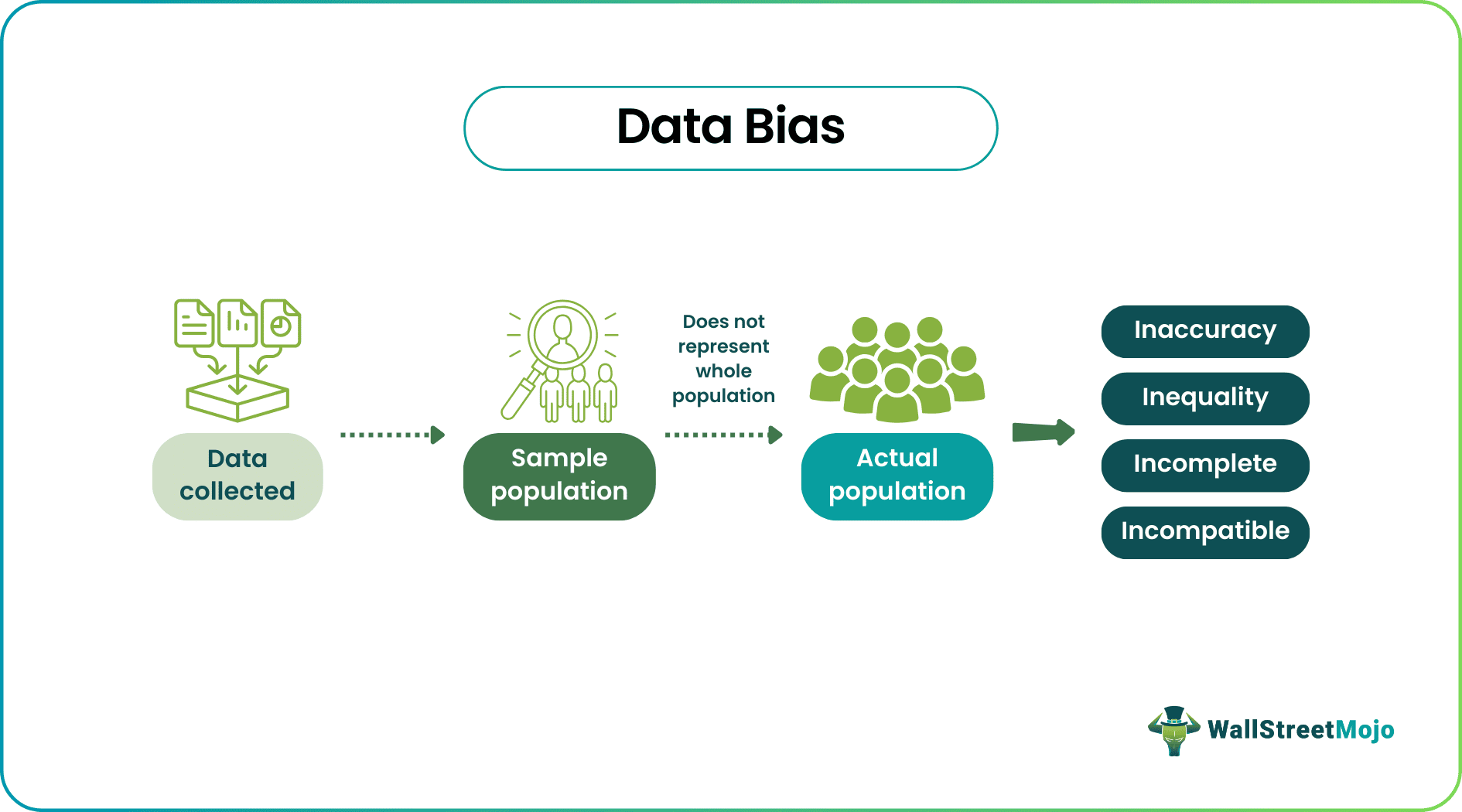
Data bias occurs when an information set is inaccurate and fails to represent the entire population. It is a significant concern as it can lead to biased responses and skewed outcomes, resulting in inequality. Hence it is important to identify and avoid them in a timely manner.
Data biases resemble human biases, such as gender stereotyping and racial discrimination. Machines replicate these biases due to the data they study, as most of it is collected from humans. These biases can be harmful and produce inaccurate forecasts with zero utility in science, finance, and economics. Furthermore, data biases can perpetuate and reinforce existing social inequalities, exacerbating societal issues and hindering progress toward fairness and inclusivity.
Key Takeaways
Key Takeaways
- Data bias refers to inaccurate, incomplete, or incompatible datasets, failing to represent the entire population.
- Common biases include gender and racial stereotypes, extrapolating the views of a few individuals to a larger group, and making generalizations.
- Data bias leads to incorrect results, renders data ineffective for its intended purpose, and contributes to systemic inequality.
- Data bias can manifest at various levels and in different forms, highlighting the pervasive nature of biases in AI systems.
Data Bias Explained
Data bias in finance refers to systematic errors or prejudices in financial datasets, which can lead to unfair or inaccurate outcomes. It can arise from various sources, such as historical, incomplete data collection, or algorithmic biases. Data bias in finance can have significant implications, including biased lending decisions, discriminatory pricing, or skewed investment strategies. Therefore, recognizing and mitigating data bias is essential to ensure fair and equitable outcomes in financial systems, requiring careful data collection, preprocessing, and algorithmic design.
Data bias in machine learning is a growing concern encompassing various forms of bias, including collection, analysis, and utilization. Biased data yields inaccurate and unreliable results, rendering it ineffective in achieving desired goals and potentially causing harm. For example, biases in facial recognition technologies have led to lower accuracy in identifying black women aged 18-30 compared to other groups, perpetuating societal inequalities.
It’s important to note that the issue lies with data collection rather than the capabilities of automated systems. These systems are efficient, but they are trained on predominantly white male faces, leading to disparities in recognition. Additionally, cameras and identification devices may not be optimized to recognize darker skin tones.
Racial and gender biases are significant concerns. However, other biases can result in inaccurate or incomplete data, such as data gathered from social media and e-commerce platforms.
Efforts are being made by programmers and internet giants like Amazon, Google, and Microsoft to develop technologies that mitigate biases, with substantial investments being made. However, the root cause of these biases lies within society itself, and unless broader societal reforms occur, machines can only do so much.
Many traders use Saxo Bank International to research and invest in stocks across different markets. Its features like SAXO Stocks offer access to a wide range of global equities for investors.
Types
Data can exhibit biases in six different ways:
- Response bias: It occurs when false or incomplete responses are recorded, leading to generalized conclusions based on a limited number of opinions. For example, social media discussions may not represent the views of the entire population due to the absence of some individuals or their lack of engagement.
- Selection bias: This bias arises when the sample population is not appropriately or suitably selected for a study. Proper randomization techniques should be employed to ensure representativeness. For instance, a study on workplace discrimination against women should have a balanced gender representation.
- Social bias: Social or label biases are gender and racial biases inherited from humans and manifested in machines and recommendation engines. Recent instances have revealed biases where artificial intelligence explained concepts in simpler terms to women than men.
- Automation data bias: This bias occurs when people tend to favor information generated by automated systems over human-generated sources. Overreliance on automation can have significant repercussions as these systems may rely on error-prone data.
- Implicit data bias: Implicit biases arise when individuals make assumptions and respond based on their experiences, often without being consciously aware of the bias. When such biases exist within the sample population, they can impact the data accuracy and data integrity.
- Group attribution bias: Group bias occurs when data is applied uniformly to individuals and groups, assuming their behavior and characteristics are the same. This generalization can be harmful and diminish the usefulness of data collection and analysis.
Examples
Study a few examples to understand data bias.
Example #1
An example of data bias in finance can be observed in credit scoring models. Suppose historical data used to train the model primarily consists of loan applications and repayment data from a certain demographic group, such as individuals from privileged backgrounds. In that case, it may lead to biased outcomes. For instance, the model might learn patterns that favor that specific group, resulting in discriminatory lending decisions against applicants from other demographic groups, such as marginalized communities. This bias can perpetuate systemic inequalities and restrict access to credit for deserving individuals based on factors unrelated to their creditworthiness.
Example #2
Suppose a group of programmers created an algorithm to detect people’s views on Twitter regarding upcoming government elections. Based on the data collected, it was forecasted that Candidate X had more support. However, Candidate Z won the elections with a 70% majority. The reason is that many people do not openly communicate their political views, and some do not use Twitter.
Example #3
Gender bias is a real concern, and ChatGPT has faced accusations of sexism. Despite attracting significant investments worth $13 billion and gaining prominence, the platform has been criticized for exhibiting biased behavior resembling mansplaining.
Forbes conducted an assessment and found that most answers provided by ChatGPT were unbiased and open-minded, suggesting that the platform leaned more towards being socially aware than sexist. However, there are instances where the platform unknowingly implies sexism. It is important to acknowledge that ChatGPT’s thinking is modeled after human behavior and that there is still progress in addressing gender bias.
How To Identify?
Several methods exist to identify biased data, although some biases may go unnoticed. Here are two key approaches:
- Assess the data source: Understand how the data was generated and if it went through any verification processes. Evaluate the efficiency and reliability of the system that collected the data. Asking these questions can provide initial insights into potential biases.
- Analyze for outliers: Examine the data for any outliers or unusual patterns. Constructing graphs or visualizations can aid in identifying any deviations from expected patterns. Investigate the reasons behind these outliers and validate their accuracy. Also, check for missing or incomplete variables in the data, and conduct exploratory data analysis to gain further insights.
How To Avoid?
Once biases are detected, avoiding them is the next step.
- One way to do so is by looking for alternative datasets which serve the same purpose but are less biased.
- Machine learning replicates human thoughts and, thus, biases too. Therefore, minimizing human biases while gathering data is another prudent step.
- Further, many benchmarks quantify discriminatory cues. It is written into the algorithm and detects such cases automatically.
- Resampling is another technique that ensures data is unbiased. However, it can be expensive and require more time and effort until the desired result is achieved.
Disclosure: This article contains affiliate links. If you sign up through these links, we may earn a small commission at no extra cost to you.
Frequently Asked Questions (FAQs)
1.What is data bias vs. data error?
Data bias refers to the presence of systematic errors or prejudices in the data that can lead to inaccurate or unfair outcomes. It arises when the data collection process or the data itself is skewed or unrepresentative of the entire population. On the other hand, data error refers to random or unintentional mistakes or inaccuracies in the data, which can occur during data collection, recording, or analysis.
2.Do all human data contain bias?
Yes, all human data can be biased to some extent. Bias can emerge from various sources, such as societal norms, cultural beliefs, personal opinions, and subjective interpretations. These biases can inadvertently influence the data collected, leading to potential inaccuracies or unfairness in the analysis or decision-making processes.
3.What is algorithmic bias vs data bias?
Algorithmic bias refers to biases that emerge from algorithm design, implementation, or use. It occurs when algorithms produce discriminatory or unfair outcomes due to biases in the data or the algorithmic decision-making process. Data bias, on the other hand, refers to biases within the data used by algorithms. It refers to biases that are reflected or encoded in the data, which can subsequently affect the outcomes or predictions generated by the algorithms.
Recommended Articles
This has been a guide to Data Bias and its definition. We explain the topic in detail, including its examples, types, how to identify and avoid it. You can learn more about it from the following articles –