Part of our Marketing Analytics guide
Introduction
Image training datasets for AI are now the foundation of modern artificial intelligence development. They support machine learning, computer vision, and other AI applications by providing the high-quality data required to build accurate and reliable models.
The landscape of AI development shows no signs of slowing down, and for good reason. AI-driven businesses can now process and utilize massive datasets that help them remain competitive, accessible, and most importantly, valuable for customers. But as generative models approach saturation, the competitive edge now lies in the provenance and granularity of training data. Choosing a dataset has become a strategic decision involving copyright safety, ethical alignment, and multimodal flexibility.
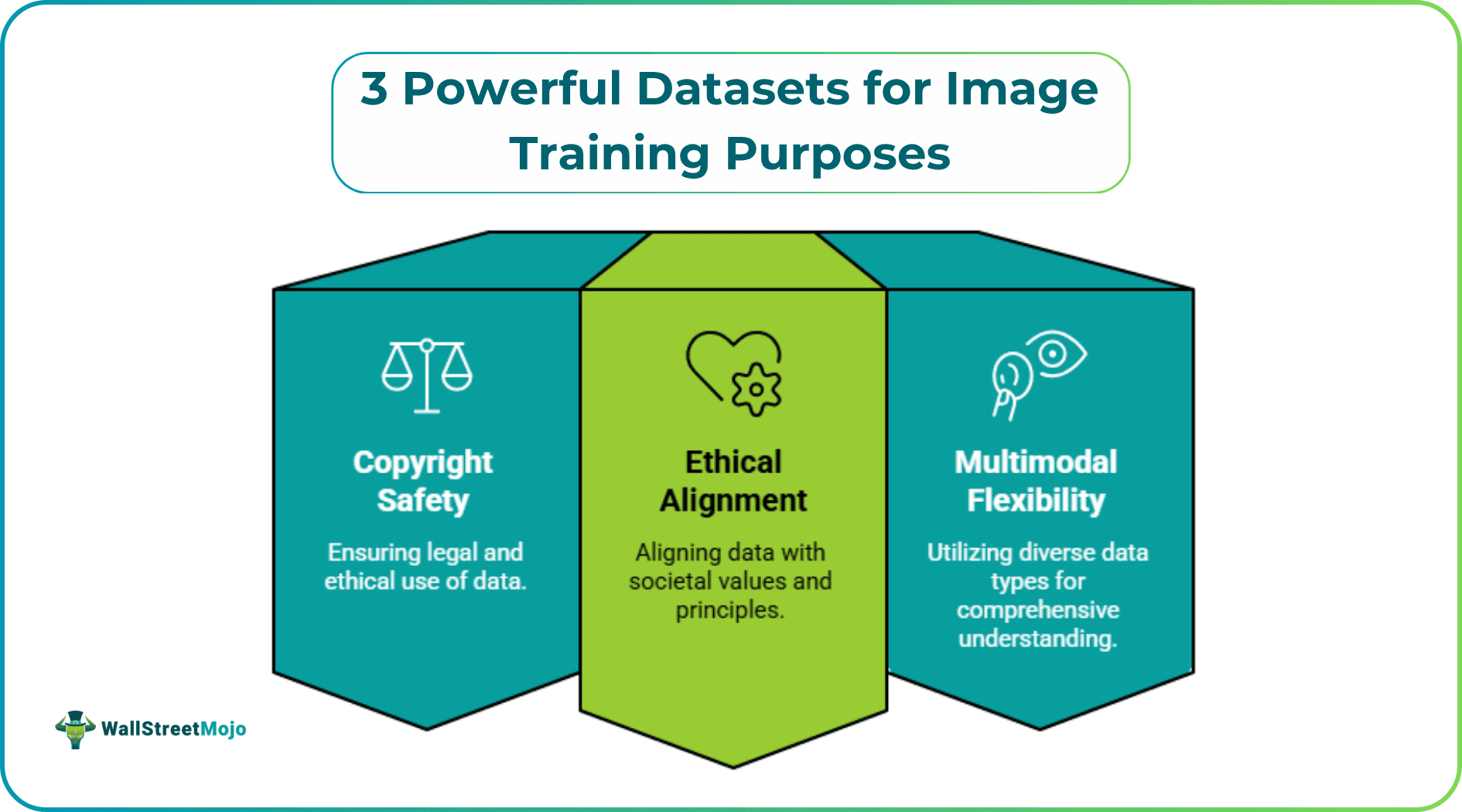
Let’s explore three industry-standard datasets that serve as the backbone for training AI and its core components, such as machine learning, computer vision, and neural networks. Read on to discover tools that provide diverse visual inputs for real-world business applications.
The Importance of High-Quality Image Training Datasets for AI
#1 – Safety
Not all image training datasets for AI offer the same level of quality, reliability, or legal protection. The industry now demands clean data to avoid legal injunctions. High-quality datasets must provide a clear chain of custody to ensure that every asset is either ethically gathered with opt-out rights or explicitly licensed. There’s a reason transparency in sourcing is a top priority. Multiple companies have faced litigation as a result of unethical data collection and processing, where models inadvertently learned to replicate watermarks or artist-specific styles.
Fortunately, this epidemic is decreasing, as brands turn to credible platforms for AI data training. Content providers with AI datasets pay careful attention to multimodal data for AI training and research purposes. This means their datasets undergo multiple rounds of human review with industry-standard compliance protocols in mind to minimize copyright infringement risks.
#2 – Validity in relation to real-world situations
AI trained in clinical isolation often fails in production. Validity refers to the environmental context here—training a retail AI to recognize a product not just on a shelf, but in a customer’s hand, under nuanced lighting, or partially obscured. For business applications, the dataset must mirror the messy, unpredictable conditions of the target industry. This fidelity is critical because it ensures the model is battle-tested and capable of navigating complex, real-world scenarios.
#3 – Annotation Accuracy
High-quality training goes beyond accurate labeling. It needs semantic segmentation and instance-level metadata. Precise annotations “sharpen” AI’s sight so it not only identifies an object as a whole but understands its integral parts (e.g., an entire vehicle vs. the boundary between the windshield and the hood). What AI is trained on dictates its annotation precision, and it mustn’t be underestimated, as it’s now critical for safety-oriented applications like medical imaging and autonomous driving.
#4 – Integration Capability
The rise of multimodal AI market standards suggests that integration flexibility is now a primary driver of technical scalability. Modern AI pipelines must align with business challenges, which requires them to be integration-ready. Datasets must follow standardized schemas that allow them to be fed directly into frameworks such as PyTorch, TensorFlow, or custom LLM-backbones.
#5 – Diversity
Diversity is the primary defense against systemic model bias, a common pitfall brands encounter when working with AI training datasets. Robust datasets address not only basic demographic representation but also long-tail scenarios. Without high variation in landscapes, settings, and edge cases, AI models suffer from overfitting, performing well on average but failing in rare cases that often matter mos
3 Best Image Training Datasets for AI
The following resources related to image training datasets for AI have been listed on the basis of certain factors, like quality, scalability, and suitability for commercial AI applications:
#1 – DepositPhotos: Multimodal training datasets for AI-driven businesses
Key features:
- Commercial indemnification: Legal safety with licensed content, helping businesses minimize risks related to copyright claims.
- Multimodal variety: Access to a massive library of 330M+ files, including images, video, audio, and 3D/CGI assets.
- Custom dataset sourcing: Ability to request curated collections tailored to specific industries and use cases.
- Rich metadata and keywords: High-density data and human-verified keywords for meaningful semantic search training.
- Global diversity: Content sourced from contributors worldwide, providing representativeness across cultures and geographies.
- Structured annotations: Professional-grade content with object labels, categories, and contextual descriptions.
DepositPhotos is a well-established content platform offering image training datasets for AI. The platform provides a structured, high-fidelity library curated for commercial model development. Its datasets are valuable for companies building brand-safe AI, where the model must avoid hallucinations of copyrighted characters or private intellectual property.

The multimodal nature of DepositPhotos’ libraries allows developers to train complex, time-aware models. If you’re looking for highly efficient datasets, DepositPhotos is a strong option. Beyond that, the content provider offers a robust API integration layer designed for automated MLOps pipelines. This means you can programmatically filter and ingest massive batches of metadata and assets directly into your training environments, bypassing manual downloads and ensuring a continuous stream of fresh, diverse data for iterative model improvement.
#2 – SA-1B: Comprehensive database for object recognition training
Key features:
- Scale: Over 1 billion high-quality segmentation masks.
- Privacy-first: Automated blurring of faces and license plates to ensure GDPR/CCPA compliance.
- Zero-shot generalization: Designed to help models identify objects they haven’t seen during training.
- High-resolution: Images with extreme detail for mask precision.
Developed by Meta AI, this 1.1B-asset dataset serves as a foundational source for large-scale training. The SA-1B dataset is often considered the definitive gold standard for instance segmentation. This is because SA-1B focuses on where the boundaries are, providing an unprecedented density of masks (averaging 100 per image).
If you are building AI for robotics or an augmented reality application where pinpointing the exact edge of an object is critical, this dataset is an excellent choice. It empowers models to perform zero-shot tasks, meaning the AI can cut out an object it has never encountered before by grasping the visual logic of boundaries.
#3 – Open Images V7 by Google: Multiclass datasets with object-location annotations
Key features:
- Point-level labels: New to V7, these provide efficient supervision by marking specific points within objects.
- Visual relationships: Annotations that describe how objects interact (e.g., a woman photographing a monument).
- Localized narratives: Synchronized voice and mouse traces that describe the image content in detail.
- Scale: 9 million images spanning over 20K different object classes.
Open Images V7 is the workhorse of the computer vision community. It detects and labels objects and explains the spatial and semantic relationships between them. The model is extremely helpful in understanding and realizing context.
Look no further than Open Images V7 if you’re searching for an AI-trained dataset for a broad, general understanding of the world. It’s a good place to start when aligning vision and natural language processing, thanks to its localized narratives feature. Just keep in mind that you might need to verify image licenses, as the platform does not guarantee the license status for each image.
Bottom Line
As image training datasets for AI continue to evolve, the future of AI-driven competitive advantage rests on the transition from broad data collection to purposeful selection. A model’s reliability in a commercial setting depends entirely on the legal and contextual integrity of its foundation. Whether DepositPhotos, SA-1B, or Open Images V7, selecting a dataset remains the most critical strategy lever for any brand aiming to deploy resilient, real-world applications. Reliable data is the primary safeguard against model bias and legal liability. At the end of the day, it often defines the difference between a prototype and a market-ready solution.
Recommended Articles
For more on Marketing Analytics, explore these related articles from our Marketing Analytics guide.