What Is Bayesian Model Averaging (BMA)?
Bayesian Model Averaging (BMA) is a statistical technique used in the context of model selection and model uncertainty. Its primary aim is to account for the uncertainty associated with selecting a single best model when there are multiple competing models that could explain a given set of data.
It provides a valuable tool for making informed decisions in various fields and domains, irrespective of the language in which it is applied. Its ability to account for model uncertainty and combine the strengths of multiple models is language-agnostic, making it a universally helpful technique for improving decision-making.
Key Takeaways
- Bayesian Model Averaging (BMA) is a statistical technique used to combine the results or predictions from multiple statistical models, each with different sets of predictor variables, in a Bayesian framework.
- BMA is widely applied in various fields, including economics, finance, environmental science, and machine learning, where combining information from diverse models enhances the quality of analysis and decision-making.
- BMA provides a more robust and accurate representation of the data-generating process, allowing for improved parameter estimation, model comparison, and prediction.
Bayesian Model Averaging Explained
Bayesian model averaging approach, often referred to as Bayesian modeling, is a robust framework for statistical analysis and inference that has its roots in Bayesian probability theory. It involves modelling uncertain quantities using probability distributions and updating those distributions as new data becomes available.
The Bayesian approach is named after Thomas Bayes, an 18th-century English statistician and theologian. However, the foundations of Bayesian probability theory can be traced back to earlier mathematicians and philosophers, including Pierre-Simon Laplace and Thomas Bayes himself. The work of these individuals greatly influenced the development of this approach.
In a Bayesian model, one starts with a prior probability distribution, representing beliefs or prior knowledge about the parameters of interest. This prior distribution encapsulates any information one may have about the parameters before observing any data. It is a crucial feature of Bayesian modeling, as it allows people to incorporate existing information or beliefs into the analysis, which is particularly useful when dealing with minor or limited datasets.
As new data becomes available, the Bayesian framework updates one’s beliefs using Bayes’ theorem. This theorem combines the prior distribution with the likelihood function, which describes how likely the observed data is for different values of the parameters. The result is a posterior distribution, which represents the updated knowledge about the parameters after incorporating the new data. This posterior distribution is the foundation for making inferences and making predictions.
Formula
The formula for Bayesian Model Averaging (BMA) involves the use of Bayes’ theorem to calculate the posterior model probabilities. Here’s the general formula for the posterior probability of a model M given data D in the context of BMA:
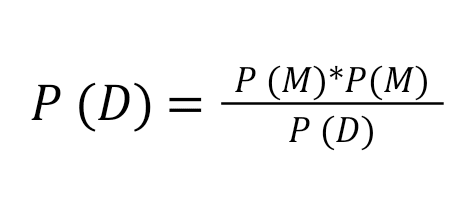
Where:
- P(M|D) is the posterior model probability, which represents the updated probability of model M being the correct or best model given the observed data D.
- P(D|M) is the likelihood of the data D given the model M. It quantifies how well the model explains the observed data.
- P(M) is the prior probability of model M, representing initial beliefs or preferences for each model before observing any data.
- P(D) is the marginal likelihood of the data D. It is the normalization constant and ensures that the posterior model probabilities sum to one over all possible models. In practice, it can be calculated as the sum or integral over all possible models in the model space.
The BMA process involves calculating this formula for each model in model space, allowing us to obtain the posterior probabilities for all candidate models. These posterior probabilities reflect the relative credibility or support for each model in light of the observed data, considering both prior beliefs and how well each model explains the data.
Examples
Let us look at the Bayesian model averaging examples to understand the concept better-
Example #1
Suppose John is a data scientist working for a company that sells a product. He is interested in comparing two different marketing strategies, Model A and Model B, to determine which one is more effective at increasing sales. John decides to use Bayesian Model Averaging (BMA) to account for model uncertainty and estimate the probability that each marketing strategy is the best.
In this analysis, John considers the following:
1. Model Space
- Model A: This marketing campaign offers a 20% discount on the product.
- Model B: This marketing campaign offers a buy-one-get-one-free promotion.
2. Prior Probabilities
John believes that both pricing strategies are equally likely to be effective, so he assigns a prior probability of 0.5 to each model:

3. Likelihoods
- John collects sales data from two different stores over a week:
- Store 1 (Model A): 100 units sold.
- Store 2 (Model B): 120 units sold.
He assumes that sales follow a normal distribution and estimates the likelihood of the data under each model:
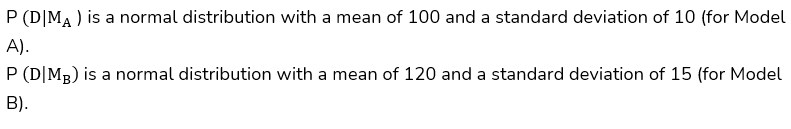
Calculation:
1. Calculate the marginal likelihood (P(D)) using the law of total probability:
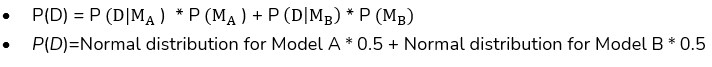
2. Calculate the posterior model probabilities:

Using the formula:
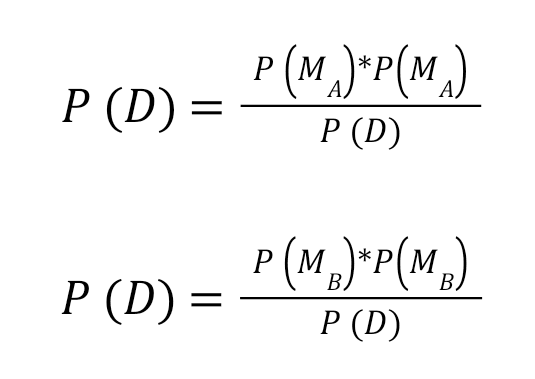
Now, plug in the values:

The results will provide John with the updated probabilities of each pricing strategy being the best, given the observed sales data and his prior beliefs. These probabilities will help him make an informed decision about which pricing strategy to adopt.
Example #2
In a healthcare study involving COVID-19 patients, Bayesian Model Averaging (BMA) outperformed traditional regression models and Gradient Boosting Decision Trees (GBDT) in predicting Length of Hospitalization (LOHS). BMA, especially when using Occam’s Window method, provided more accurate results in the final evaluation.
The study identified ICU hospitalization, age, diabetes, PO2 levels, WBC count, BUN, AST, CRP, and NLR as influential factors in LOHS. By managing these factors, healthcare professionals may reduce hospitalization duration for COVID-19 patients, enhancing both patient outcomes and healthcare resource utilization. This real-world example showcases BMA’s value in healthcare decision-making during the COVID-19 pandemic.
Applications
Application of the BDA model in various sectors-
- Econometrics: BMA is used to select and combine multiple economic models for forecasting and policy analysis. Economists can weigh the predictions of different models to make more robust and accurate economic forecasts.
- Finance: In portfolio management, BMA can be applied to combine multiple asset pricing models. This approach helps investors make better investment decisions by considering a range of possible market scenarios.
- Marketing and customer analytics: Businesses use BMA to improve customer segmentation and target marketing efforts. Combining different customer profiling models can lead to more effective marketing strategies.
- Biostatistics and epidemiology: BMA is employed to combine the results of different disease risk models, allowing researchers to estimate the probability of disease occurrence while considering various factors like genetics, lifestyle, and environmental factors.
- Political science: Political analysts use BMA to combine the predictions of different polling models and surveys for election forecasts. This approach provides a more comprehensive view of the possible election outcomes.
- Machine learning: BMA is applied in ensemble methods, where it combines the predictions of multiple machine learning models. It helps improve the overall predictive accuracy and robustness of the model, making it a common practice in competitions and real-world applications.
Benefits
The benefits of the BDA model are as follows-
- It provides complete probability distributions of model parameters and predictions, enabling a more comprehensive understanding of uncertainty. It is essential in decision-making and risk-assessment contexts.
- It allows for the specification of complex models, including hierarchical models, mixed-effects models, and models with many parameters. It accommodates a wide range of model structures, making it suitable for diverse applications.
- It is widely used in various fields, from healthcare and environmental science to machine learning and artificial intelligence. Its adaptability and broad applicability make it a valuable approach for interdisciplinary research and problem-solving.
Frequently Asked Questions (FAQs)
What is Bayesian Model Averaging in R?
To perform Bayesian Model Averaging in R, one must first define and fit multiple statistical models with different predictor variables. Then, the posterior probabilities for each model are computed using the data, and these probabilities are utilized as weights for aggregating model outcomes. The resulting averaged model offers a more dependable and robust representation of the data generation process, enabling parameter estimation and predictions while addressing model uncertainty.
Are there any software or tools to implement BMA?
Yes, there are several software options available to implement Bayesian Model Averaging (BMA). R, a popular statistical programming language, offers packages like “BMS” and “BMA” that facilitate BMA model selection and estimation. Python also provides libraries like “pymc3” and “BayesPy” for Bayesian modeling and BMA. Additionally, specialized Bayesian analysis software, such as WinBUGS and JAGS, can be used for more advanced BMA applications.
Are there any limitations or challenges in using BMA?
BMA may be computationally intensive for a large number of models, and the quality of the results depends on the accuracy of the model space and prior information. Careful consideration of these aspects is essential.
Recommended Articles
This article has been a guide to what is Bayesian Model Averaging. Here, we explain the applications, and benefits. You may also find some useful articles here –