Part of our Data Science & Machine Learning guide
Bagging Meaning
Bagging, stands for Bootstrap Aggregating, is used to improve the accuracy and stability of a model. It involves generating multiple subsets of the training data by random sampling with replacement and then training a model on each subset. The purpose of bagging is to reduce variance and overfitting in a model.
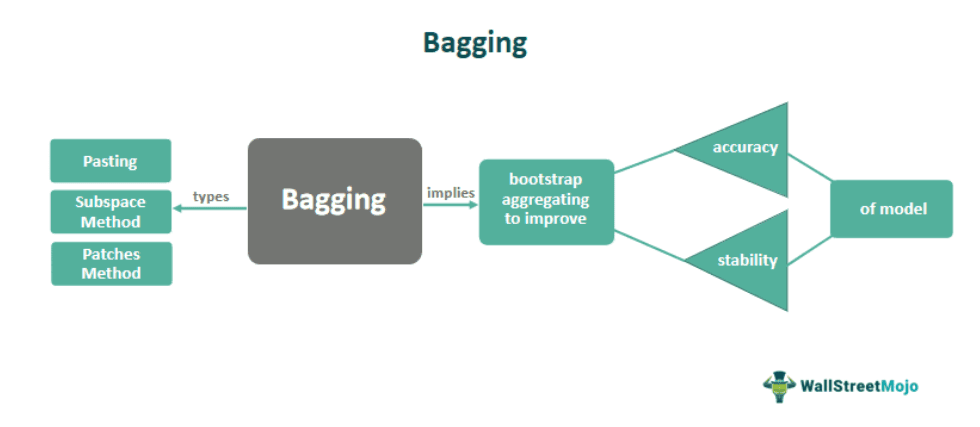
The individual models are combined by taking their predictions’ average (for regression) or majority vote (for classification). Bagging helps reduce the model’s variance and can prevent overfitting by introducing diversity into the training process. Bagging is important because it can improve the accuracy and stability of a model, particularly when dealing with high-dimensional data or noisy samples.
Key Takeaways
- Bagging is a machine learning ensemble technique that can improve the accuracy and stability of a model by generating multiple subsets of the training data and training a separate model on each subset using the same learning algorithm.
- Bagging works by introducing diversity in the training process, which helps to reduce variance and overfitting.
- Bagging can be used with any machine learning algorithm but works best with models with high variance and low bias.
- Examples of Bagging algorithms include Bagged Decision Trees.
How Does Bagging Work?
Bagging, short for Bootstrap Aggregating, is a machine learning ensemble technique used to improve the accuracy and stability of a model. It generates multiple subsets of the training data by random sampling with replacement and then training a model on each subset. Finally, the individual models are combined by taking their predictions’ average (for regression) or majority vote (for classification).
Let us look at the main steps of the bagging algorithm:
- Random Sampling: The training dataset is randomly sampled with replacement to generate multiple subsets, each of which has the same size as the original dataset.
- Training: A separate model is trained on each subset using the same learning algorithm. Each model is trained independently, so they have different perspectives on the problem.
- Aggregation: The predictions from the individual models are combined by taking the average (for regression) or majority vote (for classification) of their predictions. This produces the final prediction of the bagged model.
By combining multiple models, bagging helps reduce the model’s variance and can prevent overfitting by introducing diversity into the training process. It is commonly used with decision trees but can also be applied to other models.
One important aspect of bagging is that it requires the base model to have high variance but low bias. This means that the model should be able to fit the training data relatively well but not too tightly. Bagging can then be used to reduce the variance of the model and improve its generalization performance on new, unseen data.
Types
There are several types of bagging methods used in machine learning. Here are a few examples:
#1 – Bootstrap Aggregating
This is the original bagging method proposed by a statistician, Leo Breiman in 1996. It involves generating multiple subsets of the training data by random sampling with replacement and then training a model on each subset. Finally, the individual models are combined by taking their predictions’ average (for regression) or majority vote (for classification).
#2 – Pasting
This variant of bagging involves generating multiple subsets of the training data by random sampling without replacement and then training a model on each subset. Pasting is useful when the training dataset is large, and sampling with replacement would be computationally expensive.
#3 – Random Subspace Method
This variant of bagging involves generating multiple subsets of the features rather than the training data. A model is trained on the entire training dataset for each subset using only the selected features. This method can be useful when there are many irrelevant features in the dataset, as it allows the models to focus on the most important ones.
#4 – Random Patches Method
This variant of bagging involves generating multiple subsets of both the training data and the features. Then, a model is trained on each subset’s selected features and samples. This method can be useful when there are both irrelevant data and irrelevant features in the dataset.
Examples
Let us look at the following examples to understand the concept better.
Example #1
Suppose a data scientist is working on a project to predict whether a customer will purchase a certain product based on their demographic information and browsing history on a website. The data set consists of 10,000 customers and 50 features, and the data scientist plans to use a decision tree algorithm to build the model.
To improve the model’s accuracy and stability, the data scientist uses bagging. First, the data set is divided into subsets with 1,000 customers. Then, 25 features are randomly selected for each subset, and a decision tree is trained on that subset using only those 25 features.
Once all the decision trees are trained, their predictions are combined by taking the majority vote for each customer. If, for example, seven out of ten decision trees predict that a customer will purchase the product, then the bagged model will predict that the customer will make a purchase.
Using bagging in this way helps to prevent overfitting, reduces the variance of the model, and introduces more diversity into the training process. This technique can be useful not only for decision trees but for other types of models as well.
Example #2
An article by Built In, in an attempt to explain ensemble techniques, talks about bagging. It mentions that bagging and boosting combine multiple models to improve prediction accuracy and reduce overfitting. Bagging generates diverse subsets of the training data and trains a separate model on each subset while boosting iteratively adjusts the weights of misclassified samples to improve model performance.
Stacking is another ensemble technique that combines the predictions of multiple models using a meta-learner. These techniques are widely useful in machine learning. It has proven successful in many applications, including computer vision, natural language processing, and finance. However, it is important to carefully select the appropriate ensemble technique and avoid overfitting the model to the training data.
Bagging vs Boosting
Bagging
- Combines multiple models by averaging (for regression) or majority voting (for classification)
- Each model is trained independently, with no influence on the other models
- Reduces variance by introducing diversity in the training process
- Helps prevent overfitting by reducing variance
- Works best with models that have high variance but low bias
Boosting
- Combines multiple models by boosting the weights of misclassified instances
- Each model is trained sequentially, with each subsequent model trained to correct the errors of the previous model
- Reduces bias by improving the accuracy of the model in difficult instances
- This can lead to overfitting if the models are too complex or the learning rate is too high.
- Works best with models that have low variance but high bias
Bagging vs Bootstrapping
Bagging
- A machine learning ensemble technique used to improve the accuracy and stability of a model
- Involves generating multiple subsets of the training data by random sampling with replacement
- Used in machine learning to reduce variance by introducing diversity in the training process
- Involves training a separate model on each subset using the same learning algorithm
- Combines the predictions of the individual models by taking the average (for regression) or majority vote (for classification) of their predictions
- It can be used with any machine learning algorithm but works best with high-variance and low-bias models.
Bootstrapping
- A statistical technique used to estimate the sampling distribution of a statistic
- Involves generating multiple subsets of data, usually to estimate a statistic
- Used in statistics to estimate sampling distributions and construct confidence intervals
- Involves sampling from the original data with replacement to generate multiple datasets for analysis
- Does not involve combining models, but rather estimating statistics based on the bootstrapped samples.
- It can be used to estimate any statistic but works best with statistics that have complex or unknown distributions
Bagging vs Random Forest
Bagging
- A machine learning ensemble technique used to improve the accuracy and stability of a model
- Involves generating multiple subsets of the training data by random sampling with replacement
- Used in machine learning to reduce variance by introducing diversity in the training process
- Involves training a separate model on each subset using the same learning algorithm
- Combines the predictions of the individual models by taking the average (for regression) or majority vote (for classification) of their predictions
Random Forest
- A machine learning algorithm that uses Bagging to improve the accuracy and stability of decision trees
- Involves generating multiple decision trees on bootstrapped subsets of the training data
- Used in machine learning to reduce variance and overfitting in decision trees
- Involves training multiple decision trees on bootstrapped subsets of the data, with random feature selection
- Combines the predictions of multiple decision trees by taking the majority vote (for classification) or the average (for regression) of their predictions
Bagging vs Stacking
Bagging
- A machine learning ensemble technique used to improve the accuracy and stability of a model
- Involves generating multiple subsets of the training data by random sampling with replacement
- Used in machine learning to reduce variance by introducing diversity in the training process
- Involves training a separate model on each subset using the same learning algorithm
- Combines the predictions of the individual models by taking the average (for regression) or majority vote (for classification) of their predictions
Stacking
- A machine learning ensemble technique used to combine multiple models with different strengths
- Involves training multiple models with different learning algorithms
- Used in machine learning to combine the strengths of multiple models
- Involves training multiple models with different learning algorithms
- Combines the predictions of the individual models using a meta-model
Frequently Asked Questions (FAQs)
Is bagging random forest?
Random Forest is an ensemble method that uses bagging as its main component. It generates multiple decision trees on different subsets of the training data and combines their predictions using averaging or majority voting.
How does bagging reduce variance?
Bagging reduces variance by introducing diversity in the training process. By generating multiple subsets of the training data and training a separate model on each subset using the same learning algorithm, Bagging helps reduce individual samples’ impact on the final model. This helps to prevent overfitting and improve the model’s generalization performance by reducing the impact of outliers or noisy samples on the final prediction.
Does bagging increase bias?
Bagging typically does not increase bias in a model, as it uses the same learning algorithm on each subset of the training data. However, it can reduce variance and overfitting, which may lead to a slightly increased bias-variance trade-off.
Recommended Articles
This article has been a guide to Bagging and its meaning. We explain its examples, compare it with boosting, random forest, bootstrapping, & stacking, and types. You may also find some useful articles here –
Recommended Articles
Continue with these closely related articles from the same guide.