Part of our Data Science & Machine Learning guide
Boosting Meaning
Boosting is an ensemble learning technique combining multiple weak classifiers to form a strong classifier. The idea is to iteratively train a series of weak models and give more weight to the misclassified instances at each iteration. Its purpose is to reduce bias and variance.
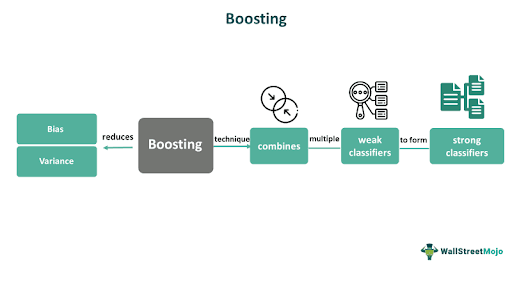
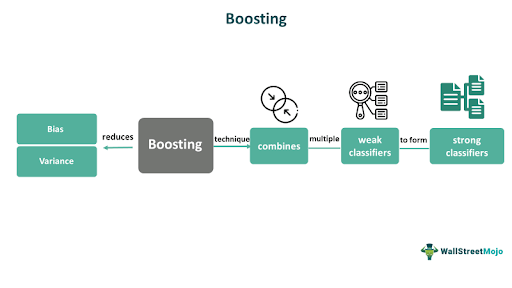
Boosting is important in machine learning because it can significantly improve the accuracy of predictive models by combining multiple weak classifiers. It makes the model more robust and effective in handling complex datasets. In statistics, boosting is a method of fitting a regression or classification model to data by iteratively adjusting the weights of the observations.
Key Takeaways
- Boosting is an ensemble learning technique that combines multiple weak learners to form a strong learner that can improve the accuracy and robustness of predictive models.
- It assigns higher weights to misclassified instances, focusing on difficult examples and reducing bias. It also uses gradient descent to optimize the model parameters in each iteration.
- Popular algorithms include Adaptive Boost, Gradient Boosting, and Categorical Boost, each with strengths and weaknesses.
- Boosting is computationally expensive, but it can significantly improve the performance of machine learning models on complex datasets.
Boosting In Machine Learning Explained
Boosting is a popular machine learning algorithm that combines multiple weak classifiers to create a strong classifier. It is an ensemble learning technique that can be used for classification and regression tasks.
The basic idea behind boosting is to iteratively train a series of weak models on different subsets of the data and give more weight to the misclassified instances at each iteration. This means that the subsequent models focus more on the instances that were difficult to classify correctly by the previous models.
Several boosting algorithms exist, including adaptive, gradient, and categorical boost. Each algorithm has its approach to creating weak classifiers and adjusting the instances’ weights. One of the key advantages is that it can help reduce bias and variance, leading to more accurate predictions. Additionally, boosting can be used with many base classifiers, including decision trees, linear models, and neural networks.
Types
Let us have a look at the types of boosting algorithms that are commonly used in machine learning:
- Adaptive Boosting: This is one of the most widely used boosting algorithms. AdaBoost creates a series of weak classifiers and combines them to form a strong classifier. Then, AdaBoost assigns higher weights to the misclassified instances in each iteration and trains a new classifier on the updated dataset.
- Gradient Boosting: It is another popular algorithm often used in regression problems. It uses an optimization method called gradient descent to iteratively fit a series of regression trees to the data. Each new tree is trained to correct the errors of the previous tree, resulting in a strong ensemble model.
- Extreme Gradient Boosting: It is a gradient-boosting variant optimized for speed and performance. It uses regularized boost to prevent overfitting and improve the model’s generalization performance.
- Light Gradient Boosting Machine: This is another variant designed to handle large-scale datasets. It uses a histogram based approach to reduce memory requirements and speed up the training process.
- Categorical Boosting: This algorithm designed to handle categorical features in the data. It combines gradient boosting and decision trees to create a robust model that can handle various data types.
Examples
Let us have a look at the examples to understand the concept better.
Example #1
Suppose a company has a dataset of customer information and wants to predict whether a customer is likely to purchase a product. Boosting can be used to train a series of weak classifiers, such as decision trees, to predict the purchase behavior of each customer.
In the first iteration, the boosting algorithm trains a decision tree on the entire dataset and assigns equal weight to each instance. However, this model performs poorly, as it misclassifies several instances.
In the second iteration, the algorithm increases the weight of the misclassified instances and trains a new decision tree on this modified dataset. This model is better than the first one but still has some misclassifications.
In the third iteration, the algorithm again increases the weight of the misclassified instances and trains a new decision tree on the updated dataset. This process continues until the specified number of weak classifiers reaches or the model performance converges.
The final model combines all the weak classifiers, and its accuracy is significantly improved compared to just a single decision tree. Based on their information, this model can be used to predict whether a new customer will likely purchase the product.
Examples #2
As per a paper published in the Journal of Medical Internet Research, boosting is a powerful machine learning technique that can potentially improve the accuracy and reliability of clinical decision support systems. Boosting combines multiple weak classifiers to form a strong classifier that can identify complex patterns and relationships in medical data. This can help healthcare providers make more informed and personalized decisions about patient care.
The paper suggests that boosting can be particularly useful in disease diagnosis, treatment selection, and outcome prediction applications. It can also help address imbalanced data in medical datasets, where rare events or conditions may be underrepresented.
Pros And Cons
Let us have a look at the advantages and disadvantages:
Pros
- Boosting can significantly improve the accuracy of predictive models, particularly on complex datasets.
- It is a flexible method for various machine-learning tasks, including classification, regression, and ranking problems.
- Boosting can handle missing data by assigning weights to each instance and focusing on the most informative samples.
- It can reduce the bias and variance of a model and thus makes it more robust to overfitting.
Cons
- Boosting algorithms can be computationally expensive and require large amounts of memory, particularly for large-scale datasets.
- It is sensitive to noisy data and outliers, which can lead to overfitting or poor performance.
- Boosting can be difficult to interpret because it involves combining multiple weak classifiers to form a complex ensemble model.
- Boosting requires careful tuning of hyperparameters, such as the learning rate and the number of iterations, to achieve optimal performance.
Boosting vs Bagging
Boosting
- Combines a series of weak classifiers to form a strong classifier
- Assigns higher weights to misclassified instances and trains new classifiers on updated datasets
- Focuses on the most informative samples and reduces bias and variance
- Can be sensitive to noisy data and outliers
- This can lead to overfitting if the weak classifiers are too complex or the number of iterations is too high.
- It can be computationally expensive and require large amounts of memory, particularly for large-scale datasets
- Examples include AdaBoost, Gradient Boosting, XGBoost, LightGBM, and CatBoost
Bagging
- Combines multiple independent classifiers to form an ensemble model
- Assigns equal weights to all instances and trains independent classifiers on random subsets of the data
- Aims to reduce variance by averaging the predictions of independent models
- Can handle noisy data and outliers by averaging the predictions of multiple models
- Less prone to overfitting due to the use of independent models
- Can be parallelized and scaled to handle large datasets
- Examples include Random Forest, Bagged Decision Trees, and Bootstrap Aggregating
Frequently Asked Questions (FAQs)
Why does boosting reduce bias?
Boosting reduces bias by assigning higher weights to misclassified instances, making them more likely to be correctly classified in subsequent iterations. In addition, this focus on difficult instances improves the model’s accuracy on the entire dataset.
What is boosting vs. random forest?
Boosting combines weak learners to form a strong learner, and the random forest is a bagging method that uses decision trees. Random forest combines bagging with feature randomization. Here each decision tree gets training on a random subset of features, reducing correlation and improving generalization.
Is boosting unsupervised?
Unsupervised learning techniques aim to uncover patterns and structures in unlabeled data without explicit feedback. So, boosting is a supervised learning technique as it requires labeled data. It is used to improve the accuracy of predictive models by combining multiple weak classifiers to form a strong classifier.
Recommended Articles
This article has been a guide to Boosting and its meaning. Here, we compare it with bagging, explain its types, examples, pros, and cons. You may also find some useful articles here –