K-Means Clustering Analysis Definition
K-means clustering analysis is a fundamental unsupervised machine learning technique used to partition a dataset into distinct clusters based on similarity or proximity. Its primary aims are data segmentation and cluster identification. It operates by iteratively assigning data points to the nearest cluster centroid and recalculating the centroids until convergence.

It aims to partition a dataset into K distinct clusters, where K is a user-specified parameter. It divides data into homogeneous subsets, which aids in data organization and simplifies subsequent analysis. Each cluster represents a group of data points with similar features or characteristics. Identifying these clusters is valuable in various applications, such as customer segmentation, image compression, and anomaly detection.
Key Takeaways
- K-Means is an unsupervised machine-learning technique that does not require labeled data and identifies natural groupings in data without pre-defined categories.
- The algorithm partitions data points into clusters based on their similarity, with the objective of making data points within the same cluster as similar as possible.
- The number of clusters (K) is a critical hyperparameter that needs to be specified by the user before running K-Means. Choosing an appropriate K is often challenging and impacts the results.
- K-Means iteratively assigns data points to the nearest cluster centroid and recalculates centroids until convergence. The algorithm aims to minimize the sum of squared distances within each cluster.
K-Means Clustering Analysis Explained
K-means clustering is a data analysis method that finds natural groupings within a dataset. Its core purpose is to categorize data points into clusters based on their similarity, with the goal of reducing intra-cluster differences.
Originating from MacQueen’s work in 1967, K-Means was initially proposed as a way to partition data points into clusters based on their distance from cluster centers. This method, known for its simplicity and efficiency, has since evolved and gained popularity in various fields, including statistics, computer science, and machine learning.
K-Means clustering identifies these clusters by repeatedly adjusting cluster centers (centroids) and assigning data points to the nearest centroid. Its primary aim is to minimize the sum of squared distances within each cluster, making it suitable for tasks such as customer segmentation, image compression, and even anomaly detection. Its simplicity, along with its roots in mathematics and statistics, has made K-Means a foundational and widely used technique in data analysis and pattern recognition.
Formula
The K-Means clustering algorithm employs a straightforward mathematical formula to partition data into clusters based on similarity. Its formula involves two primary steps: assigning data points to clusters and updating the cluster centroids iteratively.
- Assignment Step: For each data point, K-Means calculates the distance between that point and all cluster centroids. The formula to calculate the distance, typically using the Euclidean distance, between a data point (X) and a centroid (C) is:
- Distance(X, C) = √((x₁ – c₁)² + (x₂ – c₂)² + … + (x_n – c_n)²)
- Here, (x₁, x₂, …, x_n) are the features of the data point, and (c₁, c₂, …, c_n) are the features of the centroid.
- Update Step: After assigning data points to clusters, K-Means updates the cluster centroids. The new centroid of a cluster takes the mean of all data points within that cluster. The formula to update a centroid (C) is:
- C = (1/n) * Σ X_I
- Here, n is the number of data points in the cluster, and Σ X_i represents the sum of all data points’ coordinates in that cluster.
- These two steps, assignment, and update, are repeated iteratively until convergence, where the centroids no longer change significantly. The goal is to minimize the sum of squared distances within each cluster, making data points within a cluster as similar as possible.
Examples
Let us understand it better through the following examples.
Example #1
Imagine one has a large pile of colorful marbles of various sizes and wants to organize them into distinct groups based on their colors. K-Means clustering would work like this:
- Pick K (let’s say 3) initial marbles as cluster centroids, maybe red, green, and blue marbles.
- Then, measure the color similarity (distance) between each marble in your pile and these three centroids, assigning each marble to the nearest centroid.
- After this assignment, recalculate the centroids for each color group by finding the mean color of all the marbles in each group.
- Repeat these steps, updating the assignments and centroids until the centroids no longer change significantly.
Eventually, one will have clusters of marbles grouped by color, with each cluster containing marbles of similar colors.
Example #2
In the latest installment of DFS Insights for the Week 5 slate in 2023, K-Means Cluster Analysis takes center stage, providing a data-driven edge to NFL fantasy enthusiasts. This week’s analysis builds on previous strategies with significant upgrades to the methodology.
The approach involves aggregating projections from six sources, analyzing the actual results from the first four weeks, and gathering essential slate information, including the projected spread, game total, matchup ratings, salaries, value, risk, and reward metrics. To enhance accuracy, the top 250 players are singled out, and each position undergoes a factor analysis to determine the ideal number of clusters.
K-Means Cluster Analysis, a machine learning technique, is then employed to categorize players by their performance metrics. Clusters are restructured for ease of use, where Cluster 1 signifies the best performers. Notably, GPP-specific clusters are identified, offering valuable insights for specific positions.
Diagram
Imagine a grid or scatterplot representing data points in two dimensions. Let’s say a person have a dataset of points that need grouping into two groups.
In cluster 1, ‘o’ represents individual data points, and they are scattered throughout the space. Through the K-Means algorithm, these points would be assigned to one of the two clusters. It depends on proximity to the cluster centroids. The final clusters would look something like this:
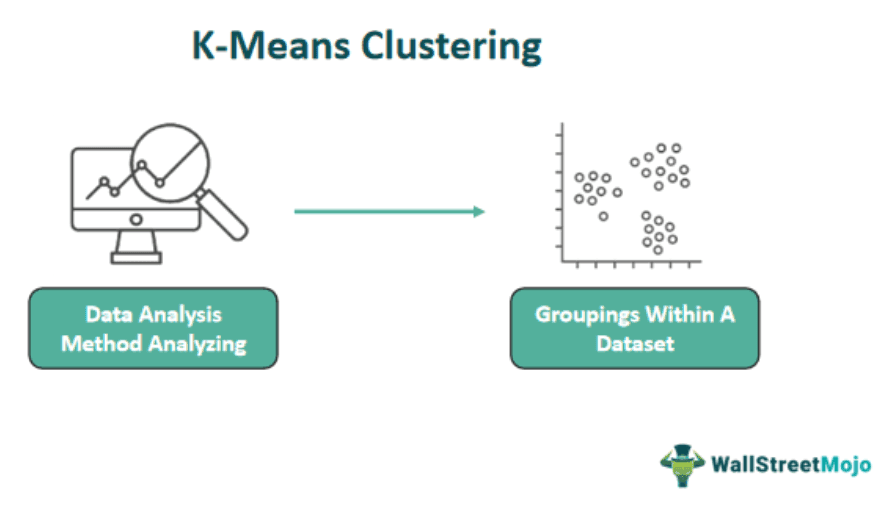
In cluster 2, ‘o’ points have been clustered into two distinct groups based on their proximity to the cluster centroids, effectively demonstrating the concept of K-Means clustering.
Applications
K-Means clustering is a versatile and widely used technique with numerous applications across various fields. Some critical applications include:
- Customer Segmentation: Businesses use K-Means to group customers with similar purchasing habits, allowing for more targeted marketing and personalized product recommendations.
- Image Compression: In image processing, it applies to compress images by reducing the number of colors while preserving image quality.
- Anomaly Detection: It helps identify outliers or anomalies in datasets, making it valuable for fraud detection in financial transactions or network security.
- Document Clustering: Text documents are put into clusters based on their content, enabling topic modeling and content recommendation systems.
- Genomic Data Analysis: Biologists use it to categorize gene expression patterns, aiding in the discovery of genes associated with specific diseases.
- Stock Market Analysis: Traders and investors apply it to segment stocks into groups with similar price behaviors, assisting in portfolio diversification.
- Geographical Data Analysis: It is for clustering geographic data, such as identifying regions with similar climate patterns or urban development characteristics.
Advantages & Disadvantages
Following is a representation of the advantages and disadvantages of using K-Means clustering:
K-Means Clustering vs K-Nearest Neighbor (K-NN)
Below is a comparison of K-Means Clustering and K-Nearest Neighbor (K-NN):
Frequently Asked Questions (FAQs)
Is K-Means sensitive to outliers?
Yes, K-Means is sensitive to outliers because outliers can significantly affect the position of cluster centroids. Outliers may lead to suboptimal cluster assignments.
Can K-Means handle categorical data?
K-Means is primarily for numerical data. For categorical data, you may need to use techniques like k-modes or k-prototype clustering.
Are there variations of K-Means clustering?
Yes, there are variations like K-Means++, MiniBatch K-Means, and hierarchical clustering, which modify or improve upon the basic K-Means algorithm to address specific challenges or needs.
Recommended Articles
This article has been a guide to K-Means Clustering and its definition. We explain its examples, formula, diagram, applications, comparison with K-Nearest Neighbor. You may also find some useful articles here –