What Is A Decision Tree?
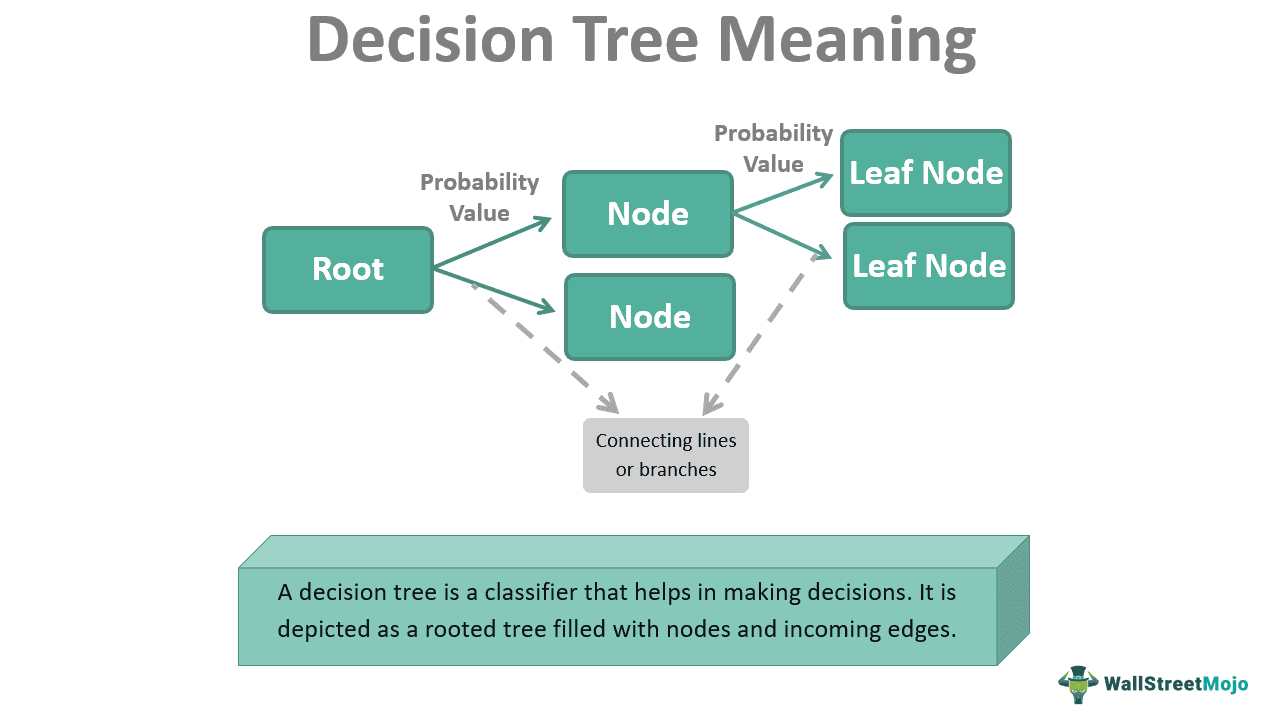
A decision tree is a flowchart in the shape of a tree structure used to depict the possible outcomes for a given input. The tree structure comprises a root node, branches, and internal and leaf nodes. An individual internal node represents a partitioning decision, and each leaf node represents a class prediction.
It is useful in building a training model that predicts the class or value of the target variable through simple decision-making rules. Given the information and options relevant to the decision, it aids businesses in determining which decision at any given choice point will produce the highest predicted financial return.
Key Takeaways
- A decision tree is a directed flowchart drawn in a structure similar to a tree. The tree structure comprises root nodes, branches, internal nodes, and leaf nodes.
- The decision-making process is carried through branching out of nodes, which depicts various possibilities where the user decides to choose or discard an option. The results or concluding nodes are called a leaf.
- The structure enables decision-making by categorizing them as best or worst
- It helps in concluding by allowing the interpretation of data visually
Decision Tree Explained
A decision tree is a classifier that helps in making decisions. It is depicted as a rooted tree filled with nodes with incoming edges. The one node without any incoming edge is known as the “root” node, and each of the other nodes has just one incoming edge. Similarly, a node with edges protruding out is an internal or test node. At the same time, the remaining nodes at the end are leaves, called terminal or decision nodes. In addition, each internal node in the structure divides the instance space into several sub-spaces by a particular discrete function of the values of the input attributes.
Each test takes into account a single attribute. Instance space then divides itself according to the attribute’s value. In cases involving numeric attributes, one can refer to it as a range. Each leaf receives a class that represents the ideal target value. In addition, the leaf may contain a probability vector displaying the possibility that the target property will have a specific value. According to the results of the tests along the path, one can categorize the instances. This is possible by moving them from the tree’s root to a leaf. In short, the stopping criteria and pruning technique directly control the tree’s complexity.
Structure
The structure contains the following:
- Root Node: The root node represents the entire population or sample. It then partitions into two or more homogenous sets.
- Splitting: The process of splitting involves separating a node into several sub-nodes.
- Decision Node: A sub-node becomes a decision node when it divides into more sub-nodes.
- Leaf or terminal nodes: Nodes that do not split are the leaf or terminal nodes.
- Pruning: Pruning is the process of removing sub-nodes from a decision node. One can describe it as splitting in reverse.
- Branch or Sub-Tree: A branch or sub-tree is a division of the overall tree.
- Parent and Child Node: A node split into subsidiary nodes is called the parent node. Sub-nodes are the offspring of a parent node
Uses
A decision tree is generally best suitable for problems with the following characteristics:
1. Instances represented by attribute-value pairs:
Instances possess fixed sets of attributes and their values. These trees aid decision-making with a limited number of possible disjoint values and allow the numerical representation of real-valued attributes such as level or degree.
2. Target functions possessing discrete output values:
It allows boolean (yes or no) classifications and functions with more than two possible output values and real-valued outputs.
3. Disjunctive descriptions:
They are useful in representing disjunctive expressions.
4. Data with missing attribute values:
The method helps reach a decision even with missing or unknown values.
In real-world applications, they are useful in both business investment decisions and general individual decision-making processes. Decision trees are widely popular as predictive models while making observations. Additionally, decision tree learning is a supervised learning approach used in statistics, data mining, and machine learning.
Examples
Check out these examples to get a better idea:
Example #1
David considers investing a certain amount. Consequently, he considers three options: mutual funds, debt funds, and cryptocurrencies. He analyses them with one priority criterion- they must give a more than 60% return. Dave understands that the associated risk is also high, but the amount he is investing is extra money he is fine losing. Since only cryptocurrencies can give such returns, he opts for them.
Check out the illustration of the decision-making process below.

Example #2
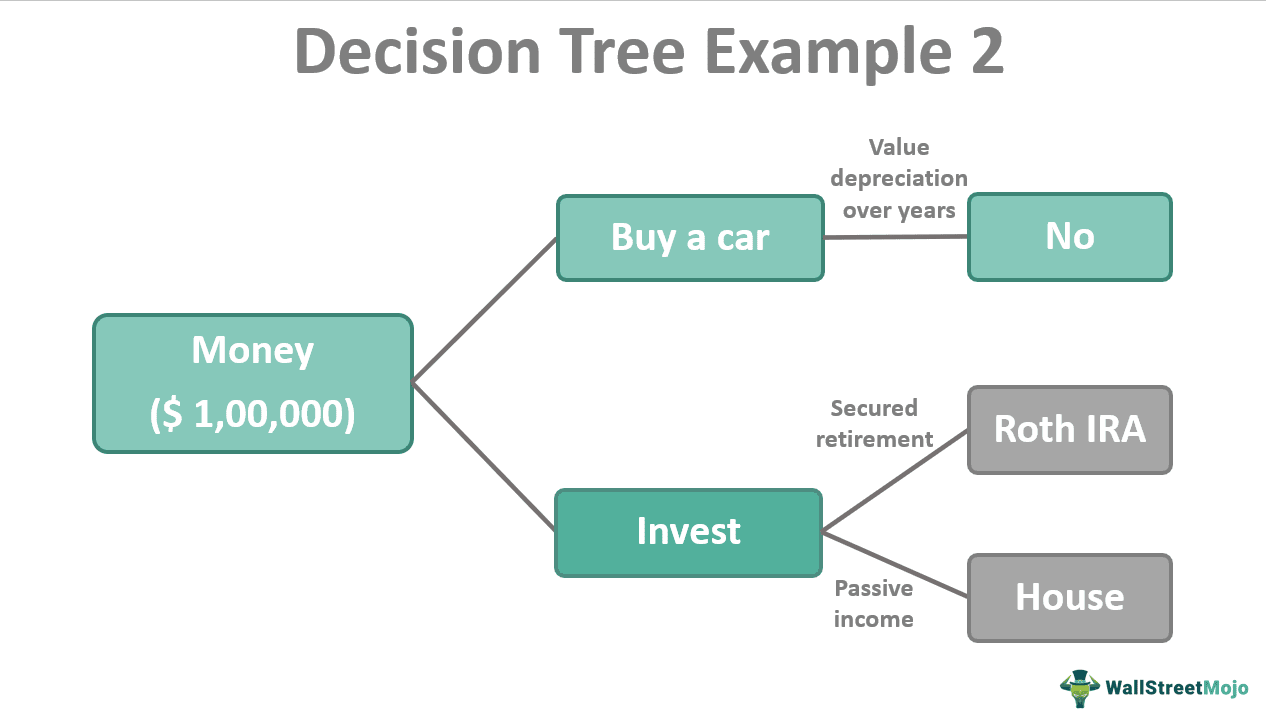
Dave has $100,000 with him. He wants to spend it but is unsure how. He knows he wants a new car but also understands that it is a depreciating asset and its value tends to reduce over time. On the other hand, he has another option- investing in it. If he chooses that option, he could split them, put them in a Roth IRA (a special individual retirement account), and use the rest to purchase a house, which can earn him passive income through rent. He, therefore, chooses to invest.
Advantages & Disadvantages
Here are the main advantages and disadvantages of using a decision tree;
#1 Advantages
- It helps in the easy conclusion of decisions by allowing the interpretation of data visually.
- The structure can be used for a combination of numerical and non-numerical data.
- Decision tree classification enables decision-making by categorizing them according to the specification.
#2 Disadvantages
- If the tree structure becomes complex, one can interpret irrelevant data.
- Calculations in predictive analysis can easily become tedious, particularly when a decision route contains numerous chance variables.
- A minor change in the data can significantly impact the decision tree’s structure, expressing a different outcome than what is possible in a normal setting.
Decision Tree vs Random Forest vs Logistic Regression
- A decision tree is a structure in which each vertex-shaped formation is a question, and each edge descending from that vertex is a potential response to that question.
- Random Forest combines the output of various decision trees to produce a single outcome. Thus, it solves classification and regression issues; this method is simple and adaptable.
- Logistic regression calculates the probability of a particular event occurring based on a collection of independent variables and a given dataset. The dependent variable’s range is 0 to 1 in this method.
While all of them are concerned with arriving at a conclusion based on probability, all three are different.
Frequently Asked Questions (FAQs)
What is a decision tree in machine learning?
Decision tree learning is supervised machine learning where the training data is continuously segmented based on a particular. It produces corresponding output for the given input as in the training data.
What is entropy in a decision tree?
Entropy controls how a decision tree decides to divide the data. Information entropy measures the level of surprise (or uncertainty) in the value of a random variable. To put it in the simplest terms, it is the measurement of purity.
How does a decision tree work?
The decision-making process is carried through branching out of nodes starting from the root node. Branching out nodes depicts various possibilities where the user decides to choose or discard that option based on preferences. The results or concluding nodes are called a leaf.
What is decision tree analysis?
Decision tree analysis is weighing the pros and cons of decisions and choosing the best option from the tree-like structure. The process includes the assimilation of data, decision tree classification, and choosing the best available option.
Recommended Articles
This has been a guide to what is Decision Tree & its definition. We explain its structure, uses, examples, advantages, disadvantages, and comparison with logistic regression/random forest. You can learn more about it from the following articles –