Part of our Data Science & Machine Learning guide
What is Gradient Boosting?
Gradient Boosting is a system of machine learning boosting, representing a decision tree for large and complex data. It relies on the presumption that the next possible model will minimize the gross prediction error if combined with the previous set of models. The decision trees are used for the best possible predictions.
The gradient boosting is also known as the statistical prediction model. It works quite similarly to other boosting methods even though it allows the generalization and optimization of the differential loss functions. One uses gradient boosting primarily in the procedures of regression and classification.
Key Takeaways
- Gradient boosting is a machine learning technique that makes the prediction work simpler.
- It can be used for solving many daily life problems. However, boosting works best in a given set of constraints & in a given set of situations.
- The three main elements of this boosting method are a loss function, a weak learner, and an additive model.
- The regularization technique is used to reduce the overfitting effect.
- An aspect of gradient boosting is regularization through shrinkage. If the learning rates are less than 0.1, it is very important to generalize the prediction model
Explanation
Gradient boosting creates prediction-based models in the form of a combination of weak prediction models. Weak hypotheses are parameters whose performance is slightly better than the randomly made choices. Leo Breiman, an American Statistician, interpreted that boosting can be an optimization algorithm when used with suitable cost functions. One does optimization of cost functions by iteratively picking up the weak hypotheses or a function with a relatively negative gradient. The gradient boosting method has witnessed many further developments to optimize the cost functions.
How Gradient Boosting Works?
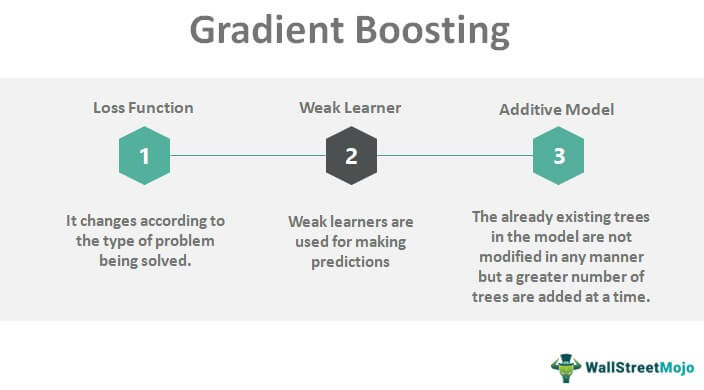
The working of gradient boosting revolves around the three main elements. These are as follows:
- A loss function
- A weak learner
- An additive model
#1 – Loss Function
The basic objective here is to optimize the loss function. The loss function changes with different types of problems. One can easily define their own standard loss function, but it should be differentiable.
As an example, we can say that regression can use the squared error & classification can use the algorithmic loss. One of the best things about gradient boosting is that with each framework a fresh boosting algorithm is not required for every loss function in question. Thus, a more generic framework would suffice.
#2 – Weak Learner
Weak learners are for the purpose of making predictions. A decision tree is basically a weak learner. Specific regression trees are used for the real output values that are used for splits. We can correct the reminders in the prediction models. Purity scores such as Gini selects the best split-points, which further construct the trees.
When it comes to another boosting technique called Adaboost, one uses single-spilled decision trees. In case of a higher number of levels (say 5 to 10), we can use larger trees. It is better to constrain or restrict the weak learners in using the number of leaf nodes or the number of layers or number of splits, or even the number of layers.
#3 – Additive Model
There are no modifications to pre-existing trees in the model, but there is the addition of a greater number of trees at a time.
At the time of adding the trees, a gradient descent procedure minimizes the losses. It minimizes the set number of parameters. In order to decrease the error, there is an updation of the weights only after calculating the error.
The sub-models of weak learners take the place of parameters. After computation of the loss, we must add a tree to the model in a way that reduce losses so that we can do the gradient descent procedure. In the end, we can add the output to the sequence of trees.
Gradient Boosting Examples
Let’s take the example of a golf player who has to hit a ball to reach the goal.
This is the available data set :

Using the pivot function, we can find the average decision for each climate condition

So for a sunny climate, the decision should be 23 (cold), 25(hot) and 52(mild). From the actual data above for day 1 & day 2, we can observe the following errors

We will calculate the above errors for all the days in the loop and make a new data set. We do this 4-5 times to calculate the errors. One can do this with the help of automated software.
The result is as follows:

Gradient Boosting Regularization
We use the regularization technique to mainly reduce the overfitting effect. M is one of the most popular regularization parameters. Thus, M denotes the count of trees in the whole model. It also eliminates degradation after the constriction of appropriate fitting procedures.
The larger the number of gradients boosting iterations, the more is the reduction in the errors, but it increases overfitting issues. Thus, we can say that monitoring the error is essential to choosing using an optimal value.
The depth of the trees in the decision tree can be an efficient parameter for regularization. It can be done as an additional measure using gradient boosting iterations. The deeper the trees, the more likely chances of overfitting the training data.
Algorithm of Gradient Boosting
The algorithm’s objective is to define a loss function & then to take measures to reduce the said function. We can use MSE, i.e., Mean Squared Error, as a loss function. It is defined as follows:
LOSS = ∑ (ý – þ)2
Where in
- Ý = the target value of function
- þ = the prediction value of function
The square of the deviations & then the summation of those squares is called a loss function.
Our objective is to reduce the loss function as near as possible to zero. To decrease the loss function, we will use gradient descent & regularise updating the prediction values. Therefore, we need to find out where the MSE is least. By using the following formula, minimum MSE can be derived:
Hence, the basic purpose is to reduce the sum of residuals to as low as possible.
Gradient Boosting Shrinkage
Another important part of gradient boosting is that regularization by way of shrinkage. Shrinkage modifies the updating rule. The updating rule is nothing but a learning rate. It has been observed that if the learning rates are less than 0.1, it is very important to generalize the prediction model. However, if the learning rate equals one, there can be a significant improvement in gradient boosting even in the absence of shrinkage. But this increases the computational time. If the learning rate is low, there are higher requirements for the number of iterations.
Frequently Asked Questions (FAQs)
What is gradient boosting in machine learning?
Gradient boosting is a boosting method in machine learning where a prediction model is formed based on a combination of weaker prediction models.
How does gradient boosting work?
The gradient boosting algorithm contains three elements. The loss function changes according to the problem at hand, weak learners who are used for making predictions, and the additive model where trees are added with a gradient descent procedure. The method predicts the best possible model by combining the next model with the previous ones, thus minimizing the error.
When to use gradient boosting?
Gradient boosting is commonly used to reduce the chance of error when processing large and complex data. In addition, it is used to create the best possible predictions in regression and classification procedures.
Recommended Articles
This has been a guide to Gradient Boosting & its Definition. Here we discuss gradient boosting regularization, how it works, examples, shrinkage & algorithm. You may also have a look at the following articles to learn more –