Degrees of Freedom Definition
Degrees of freedom (df) refers to the number of independent values (variable) in a data sample used to find the missing piece of information (fixed) without violating any constraints imposed in a dynamic system. These nominal values have the freedom to vary, making it easier for users to find the unknown or missing value in a dataset.
Degrees of freedom in statistics are significant notions in hypothesis tests, regression analysis, and probability distributions. When estimating parameters, one can obtain them by subtracting one from the total number of observations in a statistical sample. The calculation finds its application in solving problems in businesses, economics, and finances.
Key Takeaways
- Degrees of freedom (df) defines the number of values in a dataset having the freedom to vary. It helps estimate parameters in statistical analysis or finds the missing or unknown value when making the final calculation.
- The concept first appeared in the works of German mathematician Carl Friedrich Gauss (in early 1821), defined and popularized by English statisticians William Sealy Gosset (in 1908) and Ronald Fisher (in 1922), respectively.
- For a chi-square test, the degree of freedom assists in calculating the number of categorical variable data cells before calculating the values of other cells.
- It is widely applicable in businesses, economics, and finances, where it solves complex problems.
Understanding Degrees Of Freedom
Degrees of freedom first appeared in the works of German mathematician Carl Friedrich Gauss in early 1821. However, English statistician William Sealy Gosse first defined it in his paper “The Probable Error of a Mean,” published in Biometrika in 1908. In 1922, the works of another English statistician Ronald Fisher on chi-squares popularized the term.

It is the number of variables or values that are free to vary in a dataset. Knowing these independent values could help estimate parameters in statistical analysis or find the missing or unknown piece of information in a dataset. In other words, it is all but one observation that one can choose or change when making the final calculation for a data sample. Once two variables get chosen or known, the third one becomes invariable.
Degree of Freedom Formula & Calculations
For One Sample
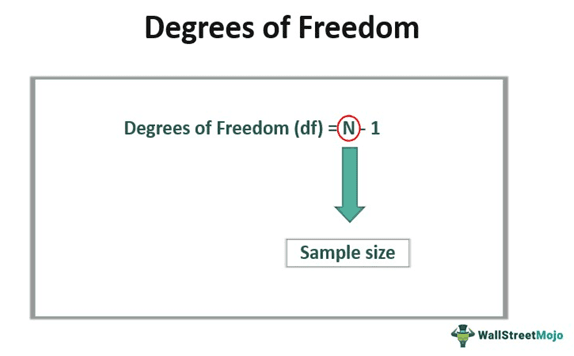
As exemplified in the above section, the df can result by finding out the difference between the sample size and 1.
df = N – 1, where N is the sample size
To understand the equation, let us consider an example where the average of any three numbers must be 8. Here, a possible dataset can have numbers 4, 8, 12. As a result, the mean of these numbers would be:
(4+8+12)/3 = 24/3 = 8
Let us consider another dataset containing numbers 3, 11, and x, where the value of x is unknown. Here, the average of the data sample and remaining values can help determine the value of x:
- Average = (3+11+x)/3
- 8*3 = (3+11+x)
- 24 = 14+x
- x = 24-10
- x = 10
It is clear from the above example that the first two independent values have the freedom to vary and could be anything. And knowing them along with the average of the dataset can help find the missing value that would remain fixed in any case. So, upon choosing numbers 3 and 11, the third number has to be nothing else than 10 to give 8, as the average for the estimate.
It is, however, valid when estimating parameters using one sample. In the above example of satisfying the average, the sample size was equal to 3. Therefore, df for a sample size of three numbers would be:
df = 3-1 = 2, where 2 represents independent values in the sample.
For Two-Sample T-Test
T-tests go into calculating the average in hypothesis tests using the t-distribution. If two samples collected are with different sizes, i.e., N1 and N2, the df would be:
df1 = N1 – 1 ——– (i)
df2 = N2 – 1 ——– (ii)
After adding two equations, the final degrees of freedom formula derived is:
df = (N1 + N2) – 2
Let us assume samples gathered for the T-tests are as follows:
N1 = 1, 4, 8, 8, 12, 14, 15
N2 = 2, 5, 9, 11
Thus, the sample size for N1 = 7 and N2 = 4. Putting the values in the formula derived above for degrees of freedom for T test will give:
- df = (7+4) – 2
- = 11-2
- = 9
Degree Of Freedom And Chi-Square Test
The chi-square test of independence applies to the data having too many ties and, to some extent, is categorical. More importantly, the chi-square table uses df to determine the number of categorical variable data cells to calculate the values of other cells.
It compares the row data with the column data to establish a relationship between two variables. In other words, each cell represents an observation or frequency for these variable inputs. It also helps reject a hypothesis based on the number of variables and data samples available.
For example, a medical center conducts a study to establish a relationship between gender and body fat percentage. It is where the chi-square test can help determine how two sets of categorical data are related. The null hypothesis, in this instance, will be the non-existence of any relationship between gender and body fat percentage. On the other hand, the alternative approach would indicate the existence of a connection between two variables.
The degrees of freedom in chi square test would be:
df = (r-1) * (c-1)
Where r is the number of rows and c is the number of columns.
Example
Let us move ahead with the abovementioned example to find out the df. The set of observations obtained by the medical center is as follows:
| Gender | Body Fat Percentage (approx.) | ||||
| Male | 15 | 18 | 20 | 12 | 15 |
| Female | 22 | 21 | 25 | 18 | 22 |
If the number of rows with samples from different gender (m/f) = 2 and the number of columns with the respective body fat percentage = 5, then
- df = (2-1) * (5-1)
- = 1*4
- = 4
Frequently Asked Questions (FAQs)
What is Degrees of Freedom?
Degrees of freedom (df) denotes the number of independent variables or values using which the information missing from a dataset could be derived or found. It is an effective tool to estimate parameters in statistical analysis in businesses, economics, and finances.
What are the degrees of freedom for chi-square?
The chi-square test of independence uses degrees of freedom to calculate the number of categorical variable data cells to calculate the values of other cells. The df in the chi-square test would be:
df = (r-1) * (c-1)
Where r is the number of rows and c is the number of columns.
How do you calculate degrees of freedom for ANOVA?
The analysis of variance (ANOVA) compares known means in a dataset, whereas df refers to the total number of observations across all cells. The calculation for df for ANOVA is:
df = N – k, where N is the data sample size and k is the number of cell means, groups, or conditions.
For example, if the number of observations for all cells in a dataset is 40 and the mean is 5 –
df = 40-5
= 35
Recommended Articles
This has been a guide to Degrees of Freedom and its definition. Here we discuss the formula to calculate degrees of freedom along with examples. You can learn more from the following articles –